
July 8, 2019

In the past week, I have had calls to our partners in both Tokyo and India to discuss how they can best use the data to improve their workflow and availability. While we work with several rugby teams, we work with far less in cricket. Naturally, there was a hesitance from our Indian National Cricket Team users to want to use our database simply because we don’t have many cricket athletes in there, let alone athletes of Indian descent. This would make sense at first thought, but our partners in Bangalore have seen results similar to that of our American football partners. How could this be?
Without question, one of the most frequent requests we get is wanting to see a database with only “insert sport here” to see how their individuals stack up. Intuitively, it makes sense to see how your shortstop compares to others in the database, but it needs to be understood that just because this data is normal for a shortstop, it doesn’t mean it is ideal. To look only within the skill, or sport as opposed to a whole aggregate database for comparisons is often considered “overfitting.”
What is overfitting?
In statistics, overfitting is the production of an analysis that corresponds too closely or exactly to a particular set of data, and may, therefore, fail to fit additional data or predict future observations reliably. It is easy to see how this can relate to a specific skill/sport database as well. For example, a unit of elite special forces might all have similar absolute scores for force plate variables, but these patterns may be a result of similar background and training history – such as boot camp training.
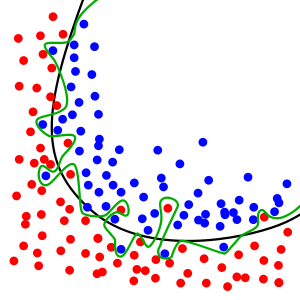
Above: The green line represents an overfitted model and the black line represents a regularized model. While the green line best follows the training data (unique sport), it is too dependent on that data and it is likely to have a higher error rate on new unseen data, compared to the black line.
Asking better questions
Like training, getting too specific before laying a general strength foundation is probably not a good idea. Having a broad aggregate database across dozens of organizations with people of all shapes and sizes is the best way to identify norms that apply to human movement, not necessarily specific sports. Instead of wondering how your athletes compare to those in the same sport, focus on your athletes moving better than they do now – regardless of sport. Movement is universal, and skills are the separator.
Human-specific, not sport specific
Think about the traditional mindset of writing up plans for baseball pitchers compared to position players. You are assuming that Craig Kimbrel (6’) moves similar to Jon Rauch (6’11) – and Albert Pujols to Billy Hamilton. As I’ve been told many times – play the man, not the game. Each deserves a plan to address their specific movement sequencing, so while they all play the same game their movement strategies are often times a far cry apart.
More meaningful as a whole
Just as what they discovered in the blood work results, we found there is more similarity between positions across different populations (Offensive Lineman in Football – Front Row in Rugby – Catcher in Cricket) than within select populations (Pitcher to Center fielder). What do all of these have in common? They are required to squat to play their position. If we chose to divide our database into several pieces we would still see it reliable, but with less statistical power (than segmenting via gender) than one might assume – and for the practitioner that means less understanding, or context to drive the training process.